
TCP/IP networking basics: hubs, switches, gateways and routing
TCP/IP networks are the most common type of network today. With such a network, a number of computers or nodes can communicate with each other. An important aspect of this communication is routing: getting data packets from one node to another, in particular from one node on one network to another node on another network.
Nodes, hubs and switches
A network is a collection of computers or other devices, commonly called nodes, that are able to communicate with each other. This communication takes place on different network levels. A network may use the Internet Protocol (IP) at one level and Ethernet at the level directly below it. This distinction is important because some parts of the network operate at the IP level and others at the Ethernet level.
The most common type of network (especially in the home) is the Ethernet network shown in figure 1, where all nodes are connected to a central device. In its simplest form this central node is called a hub.

Figure 1: a basic network architecture
Basically, a hub is a box with lots of connections (sockets) for Ethernet cables. The hub repeats all messages it receives to all connected nodes, and these nodes filter out only the messages that are intended for them. This filtering takes place at the Ethernet level: incoming messages carry the Ethernet network address of the intended recipient.
A problem with this approach is that hubs generate a lot of traffic, especially on larger networks. Most of this traffic is wasted, since it is intended for only one node but it is sent to all nodes on the network.
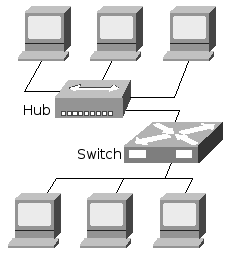
Figure 2: a basic network with a hub and a switch
A commonly used solution today is a switch. A switch still connects all nodes to each other, like a hub, but is more intelligent in which messages are passed on to which node. A switch examines incoming Ethernet messages to see which node is the intended recipient, and then directly (and only) passes the messages to that node. This way other nodes do not unnecessarily receive all traffic.
Since switches are more expensive than hubs, a low-traffic part of the network could be set up using a hub, with the more high-traffic nodes being interconnected to the switch. The hub segment is then connected to the switch as well, as shown in figure 2.
Segments and bridges
A large network can be divided into multiple parts which are called segments. Each segment can use its own network protocol, security rules, firewalls and so on. Nodes on different segments cannot directly communicate with each other. To make this possible, a bridge is added between the segments, as shown in figure 3.

Figure 3: two network segments connected via a bridge
The bridge lets packet pass that are destined for a host on the other side. This seems to turn the two segments into one big network again, but there is an important difference. Data packets generated on one segment and intended for that same segment are not passed to the other segment. This saves on data transmission on the network as a whole.
Routers and routing
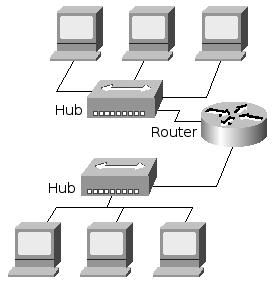
Figure 4: two networks connected via a router
The above examples all presented a single network at the Internet Protocol level. Even when the network is segmented, all nodes are still able to communicate with each other. To connect networks, a router or gateway is used.
Routers and gateways
A router is connected to two different networks and passes packets between them, as shown in figure 4 to the right. In a typical home network, the router provides the connection between the network and the Internet.
A gateway is the same as a router, except in that it also translates between one network system or protocol and another. The NAT protocol for example uses a NAT gateway to connect a private network to the Internet.
Routing messages between networks
When a node on one network needs to send a message to a node on another network, this packet will be picked up by the router and passed on to the other network. Many nodes are programmed with a so-called 'default gateway', which is the address of the router that is to take care of all packets not for other nodes on the same network.
Routers maintain a so-called routing table to keep track of routes: which connections (to different networks) are to be used for which faraway networks. Some of these routes are programmed in manually, but many are "learned" automatically by the router. Modern routers inform each other about new routes and no longer working routes to make this as efficient as possible.
Figure 5 below illustrates how routers (and behind them, entire networks) may be connected. There are now multiple routes from the node at the left to the node at the right. Since routers transmit IP packets, and IP packets are all independent of one another, each packet can travel along a different route to its destination.
The TCP protocol that runs in the transport layer above does not notice this, although a user may notice if suddently the connection seems faster or slower. That could be caused by packets now following a different route that is faster or slower than the old one.

Figure 5: how two nodes on different networks can communicate with each other
Security of routing
Routing data packets in this way is very efficient, but not very secure. Every router in between the source and the destination can examine every packet that comes through. This enables for example systems like Carnivore (in Dutch) to examine almost all Internet traffic. Using encrypted Internet transmissions avoids this.
An additional risk is traffic analysis. A router can see where packets come from and where they go to. Even if the content of the packets is encrypted, the source or destination address itself already reveals something about the communication. For example, a corporate IP address that sends data to a newspaper website may indicate leaking of business secrets.
Onion routing with systems like Tor avoid even this risk, although they are much slower than traditional routing systems.