
TOR: The Onion Router
TOR or Tor is an abbreviation for The Onion Router. As the Tor homepage puts it "Tor is a network of virtual tunnels that allows people and groups to improve their privacy and security on the Internet." Tor uses so-called onion routing to defend against privacy attacks. Onion routing relies on multiple layers of security that are removed (like onion skin) one by one as a message is routed through the Tor network.
To explain what onion routing is, I will elaborate on Tor as this is the leading software utilising onion routing. I will first give a short introduction what routing and routing protocols are, there after which technologies are used to achieve enhanced communication anonymity and subsequently, how Tor makes use of these techniques and in which way it differs from (traditional) onion routing.
Introduction to routing
Routing can be defined as the complete system of selecting appropriate paths in a computer network along which data should be sent or forwarded from one location to another. This path is built out of a string of nodes, which all receive a data packet and subsequently send it to the next node in the path. This path should result in the most efficient and effective connection between location A and location B.
The rules: routing protocols
Routing is most effective if one or more routing protocols are in use. A routing protocol is in essence a set of rules used by nodes to determine the most appropriate paths into which they should forward packets towards their intended destinations. A routing protocol specifies amongst others how intermediary nodes report changes in the network and share this information with the other nodes in the network.
Without a routing protocol, the network cannot dynamically adjust to changing conditions, resulting in the fact that all routing decisions are predetermined and thus static.
Routing in practice: an example
I will use a simplified example to clarify these definitions however the principle is the same irrespective of the scale of the network. If Alice would like to connect to Bob, she sends a request to her ISP to find out which route should be used to make a connection and her provider will respond with the routing information.
After Alice's computer received the route to be used the request will be split into smaller data packets and sent to the first node which in turn sends the packet to the consecutive nodes to eventually reach Bob.
A risk: Traffic analysis
Even though routing is being used on an everyday basis and its use is widespread, it does have a disadvantage. Public networks like the Internet are very vulnerable to traffic analysis because, e.g. packet headers identify the IP addresses of the recipient(s) and the packet routes can rather easily be tracked.
Of course transmissions can be encrypted, so that an attacker cannot learn the content of these transmissions. This however still reveals the fact that two parties are communicating. If for example a government official is sending encrypted data to a website of the opposition, and later that site publishes a document that was supposed to be secret, it is pretty clear what happened.
To explain how enhanced communication anonymity can be reached I will give an overview of two extensively used approaches. First of all digital mixing and afterwards anonymizing proxies.
Digital mixing

Figure 1: Encryption in three layers
In the early eighties of the last century, David Chaum invented the principle of digital mixes (sometimes called mix networks) to achieve a higher level of anonymity with personal communication. Digital mixing uses a similar system as routing but it adds several layers in the connection between the sender and receiver of the communication. Figure 1 illustrates how these layers function in practice. The layers are created using public key cryptography.
Mixing the message
If Alice wants to send a message to Bob, without a third person being able to find out who the sender or recipient is, she would encrypt her message three times with the aid of public key cryptography. She would then send her message to a proxy server who would remove the first layer of encryption and send it to a second proxy server through the use of permutation. This second server would then decrypt and also permute the message and the third server would decrypt and send the message to the intended recipient. This is illustrated in the figure below.

Figure 2: Digital mixing - a three-layered encrypted message being processed
Using digital mixing is comparable to sending a letter encased in four envelopes pre-addressed and pre-stamped with a small message reading, "please remove this envelope and repost". (With the difference of course that the encryption of the message is not easily removed as an envelope.) If the three successive recipients would indeed post the letter, the letter would reach the intended recipient without there being a paper trail between the initial sender and the intended recipient.
Security of digital mixing systems
This system is effective because as long as the three successive recipients, the re-senders, send enough messages it is impossible for a third person e.g. an ISP, and subsequently government (policing) agencies, to find out what message was originally sent by whom and to whom.
Digital mixing also has some downsides. First of all, it only works if the re-senders send enough messages (at any given moment and during a set amount of time e.g. a day). However, because (most) nodes, the resending servers, do not send enough messages at the same time, digital mixing would be vulnerable to statistical analysis such as data mining by governments or government policing agencies.
By making use of e.g. a threshold batching strategy the proxy servers are able to solve this lack of messages at the same moment. However, this results in the fact that the period between the sending and the eventual receiving of the message by the intended recipient can be several hours depending on the amount of messages deemed critical. Which means a threshold batching strategy makes digital mixing a (rather) slow technique.
And because the use of public key cryptography in itself is not very fast, it would not take several hours for a series of proxy servers to decrypt and permute a message but it would be significantly longer than a normal transfer lasting milliseconds.
This all results in the conclusion that digital mixing is only effective in case of static data packages such as e-mails, because if digital mixing were to be used for web browsing or data transfer a high latency would be the result. This in turn means that digital mixing is not a suitable solution for one who wants anonymity while web browsing or conducting data transfers with the aid of e.g. FTP servers.
Anonymizing proxies
An anonymizing proxy server is a server whose only function is to be a node. This means it only reroutes requests from one location to another. If Alice wants to make a connection to Bob without him knowing that it is Alice connecting to him, she would fill in Bobs IP address at a proxy server. The proxy server would then make a connection to Bob and relay all the information Bob sends to it to Alice.

Figure 3: An anonymizing proxy connecting several nodes
The system of proxy servers has many positive aspects. Firstly it is useable for both static-, e.g. e-mail, and dynamic data packets, such as web browsing. Secondly, proxy servers do not require expensive techniques like public key encryption to function, and thirdly it is an easy system. A user only needs to connect to a proxy server via his or her web browser to use it, as is illustrated by figure 3 above.
However, anonymizing proxies have one fatal flaw, which makes them less than reliable for anyone who wants anonymous communication. If an unreliable third party controls the proxy server, e.g. a group of criminals who use the proxy server for phishing, the user is no longer guaranteed of a secure, and anonymous, communication.
Onion routing with Tor
Instead of using one specific technique of the aforementioned techniques, Tor combines specific aspects of both digital mixing and anonymizingg proxies. I will first explain how using Tor can enhance anonymity to elaborate afterwards on the differences between Tor and classic onion routing (Wikipedia).

Figure 4: How Tor works (1) - getting a directory listing
Connecting to the Tor network
If Alice wants to make a connection to Bob through the Tor network, she would first make an unencrypted connection to a centralised directory server containing the addresses of Tor nodes as illustrated. After receiving the address list from the directory server the Tor client software will connect to a random node (the entry node), through an encrypted connection. The entry node would make an encrypted connection to a random second node which would in turn do the same to connect to a random third Tor node.
That third node, the exit node, would then connect to Bob as visualised below. Every Tor node is chosen at random (However, the same node cannot be used twice in one connection and depending on data congestion some nodes will not be used.) from the address list received from the centralised directory server, both by the client and and by the nodes, to enhance the level of anonymity as much as possible.

Figure 5: How Tor works (2) - Alice connecting to Bob
Changing routes
If the same connection, the same array of nodes, were to be used for a longer period of time a Tor connection would be vulnerable to statistical analysis, which is why the client software changes the entry node every ten minutes, as illustrated.
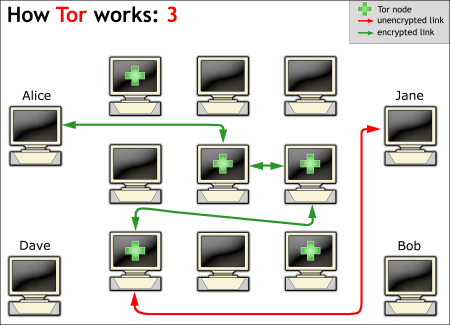
Figure 6: How Tor works (3) - the route to Bob changes
Increasing anonymity by becoming a node
To increase anonymity Alice could also opt to run a node herself. I mentioned earlier that the identity of all Tor nodes is public, which could lead to the conclusion that running a node would not increase the level of anonymity for Alice. This notion would however not be correct.
I will try to explain why running a Tor node actually increases anonymity. If Alice uses the Tor network to connect to Bob, she does this by connecting to a Tor node, however if she functions as node for Jane she would also connect to a Tor node. This would result in a situation in which a malevolent third party would not be able to know which connection is initiated as a user and which as node.
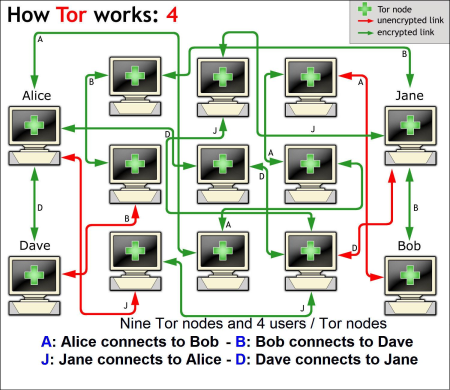
Figure 7: How Tor works (4) - Alice as a Tor node
Which means this makes data mining significantly more difficult, and in a situation where Alice functions as a node for dozens of users, it makes data mining virtually impossible. As Roger Dingledine said it poignantly, "Anonymity loves company [...] it is not possible to be anonymous alone". This is also one of the reasons why the United States Department of Defence funded and still funds, amongst others through organisations such as DARPA and CHACS, the research, development and refinement of Tor.
Differences with other systems
Besides the obvious differences, Tor is usable for both low and high latency communication and it is not reliant on one (possibly comprised) server, Tor differs significantly from digital mixing and anonymizing proxies. There are many technical differences but I will limit myself to three positive differences and two negative differences.
Positive aspects of Tor
First of all the principle of digital mixing is based on the fact that the communication initiator, and in some cases the recipient (e.g. with nym-based mailing), knows all the servers which are used to communicate with and to a third party. This means that when a recipients or initiators computer is compromised, the whole chain is no longer anonymous. In the same situation, but using Tor, the malevolent third party would only know the entry nodes to which that computer connected.
A second positive aspect is that digital mixing relies on a rather static and limited amount of nodes, which Tor does not. If a malevolent third party would monitor all possible relaying nodes in a digital mixing system, e.g. fifty, it would be possible for even a modest adversary to correlate information through traffic analysis to would form a robust attack (as was proven by Nick Mathewson and Roger Dingledine (PDF, 247kB) in May 2004). This is not possible in the case of Tor because of the fluctuating number of Tor entry-, relaying- and exit nodes.
A third positive aspect in which Tor also differs is the fact that it is possible for users to be a node themselves. This has three advantages, first of all it makes monitoring all nodes more difficult, secondly it reduces the latency of all nodes and thirdly, and perhaps most importantly, it makes it possible for an individual user to increase his or her (and other users') anonymity.
Negative aspects of Tor
The fact that it is possible for individual users to run a Tor node is also a negative aspect of Tor in comparison to classical onion routing. Through this option, a malevolent third party with enough resources could compromise the anonymity of all users by adding a significant number of nodes to the network and perform analysis of all traffic through these compromised nodes. A small-scale experimental set-up by Murdoch and Danezis (PDF, 364kB) in November 2004 proved that traffic analysis is theoretically possible by adding a corrupt server. However, Murdoch and Danezis were neither capable of ascertaining the initiator of the communication nor the user connected to the node.
A second less positive difference between Tor and classical onion routing is the use of, or rather lack of, a batching strategy like the aforementioned threshold batching strategy or e.g. the timed dynamic-pool batching strategy utilised by Mixminion. Tor does not use any specific batching strategy, which means that data packets are processed and permuted as soon as they are received; whereas digital mixing systems wait for a critical amount of data packets before permuting them to the next server or the intended recipients.
Whether or not Tor should use a batching strategy was a design objective proposition requiring an assessment of on the one hand a higher latency and on the other hand a form of communication that is slightly more traffic analysis sensitive. Since a low latency network was deemed most important for web browsing, utilising a batching strategy was not a design option however it is still considered for future refinements of Tor.